
目次
今回のブログは大規模言語モデルのGPT-4に麻雀をいろいろ教えていく、その1で、まずは牌画像を読み込んでもらいます。
GPT-4は最近マルチモーダル化していて、テキストだけでなく、画像を読み込んだり、画像を生成したり、雑談などの会話のやり取りができたりで、なんともすごいAIに進化しています。
これらの機能は有料バージョンのChatGPT Plusで課金しないとダメです。
これをクリアすると無料のGPT-3.5ではなく、GPT-4が使えるようになります。
すると上記のマルチモーダルがいろいろ利用できると。
おまけにテキストの応答の精度も格段に上がるので、仕事で使ったり、書きものをしたり、画像を作ったり、そんなことを常にしている人たちは、GPT-4をおすすめします。
さて、今回はこのGPT-4に麻雀を教えていきます。
結構単純な麻雀のルールは知っているようですが、全体的にはイマイチ。
役についてもよくわからんようです。
初回の今回は、まず牌の画像を読んでもらうこと。
日本語は英語よりも苦手な上、牌には漢字で文字が描かれていたりするので、一発での理解は難しいでしょう。
なので、教えながら、理解してもらう計画です。
GPT−4について知らない方もいると思うので、まずはこいつのいろんな機能を見ていきみましょう。

GPT-4とは
みなさん、GPT-4って聞いたことありますか?
これがすごいAIなんです。
OpenAIっていうチームが作ったんですけど、前に流行ったGPT-3なんかの後継機なんです。
名前の「GPT」、実は「Generative Pre-trained Transformer」の略なんですよ。難しそうな名前ですけど、要は「すごく賢い機械」ってことですね。
GPT-4、正直言ってスペックがとんでもない。文章を人間みたいにサラサラ書けるし、質問に答えたり、翻訳もバッチリです。
でも、一番のビックリポイントは、画像認識と生成もできるようになったこと!
テキストだけじゃなく、画像を見て、それに関する文章や画像もポンと生成できるんです。
で、何でこんなに賢いのかというと、裏側で動いてる「ディープラーニング」って技術のおかげです。
これ、ものすごくざっくり言うと、大量のデータをガツガツ食べて賢くなるっていう仕組みです。
GPT-4の登場で、これからのAIの世界、絶対に面白くなりそうですよね。
どんなことができるようになるのか、ワクワクしながら見守りたいです。
GPT-4の画像認識とは
さて、画像認識をまずいってみましょう。
画像認識っていうと、もしかして「AIが画像を見て、何が写ってるか分かる」ってイメージですか?
まあ、それも間違いじゃないですけど、GPT-4の場合はもっとスゴイ。
画像を見て、その内容に合わせて文章をサクッと生成することができるんです。
たとえば、猫の写真を見せると「この猫、めちゃくちゃ可愛いですね!」とか、富士山の画像には「富士山、雄大でキレイですね!」って感じで、文章を作ってくれるんです。
なんでこんなことができるのかというと、ものすごくシンプルな理由。
GPT-4は、膨大な量のテキストデータと、それに関連する画像データを学習してるんです。
だから、画像を見ても、それに関する知識や文脈が頭の中にギッシリ詰まってるわけですね。
この機能、考えてみれば使い道いっぱいで、例えば、あなたが旅行に行って撮った写真をGPT-4に見せれば、その写真の解説や背景をちょっとした文章で教えてくれるかもです。
画像を読み描きができれば、AIとのかなりの意思疎通ができるようになるってことです。
GPT-4の画像認識、これからの時代にかなり役立つ仕組みになるでしょう。

GPT-4に麻雀牌の画像を読んでもらう
では、早速GPT-4に麻雀牌の画像を読んでもらいましょう。
まずはこちら。
GPT-4に下記の画像を入れてみました。

ウーマン
チーピン
パーソウ
さてさて、認識できるのかチェックです。
プロンプト
この画像には何が描かれていますか?
左の画像から順番に答えてください。
GPT-4の回答
左の画像には「中」という文字が書かれた麻雀の牌が描かれています。これは赤い中の字牌です。
中央の画像には4つの麻雀の牌が描かれています。これは4つの白板牌です。
右の画像には緑の竹牌が描かれています。これは8筒の牌です。
最後はパーソウですね。パーピンと言ってますが、これでは不正解。惜しいですけど。
やはりこちらの予想通り、牌の読み込みは苦手なようです。
で、ここで、正解を教えます。
正解を教えます。
左から、
ウーマン
チーピン
パーソウ
と呼びます。
ここまで理解しましたか?
ChatGPT
はい、理解しました。指摘していただき、ありがとうございます。ウーマン、チーピン、パーソウと覚えておきます。次回から正しく答えられるようにします。
プロンプト
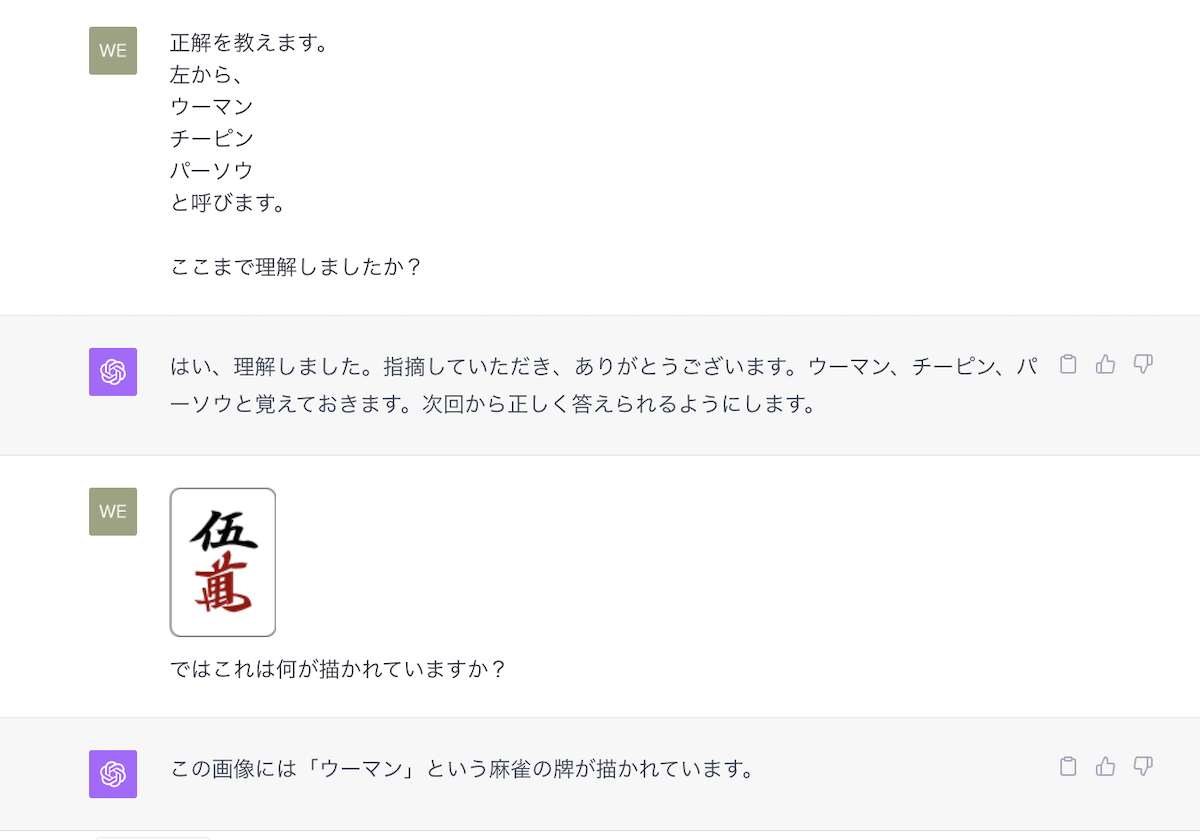
ではこれは何が描かれていますか?
ChatGPT
この画像には「ウーマン」という麻雀の牌が描かれています。
プロンプト
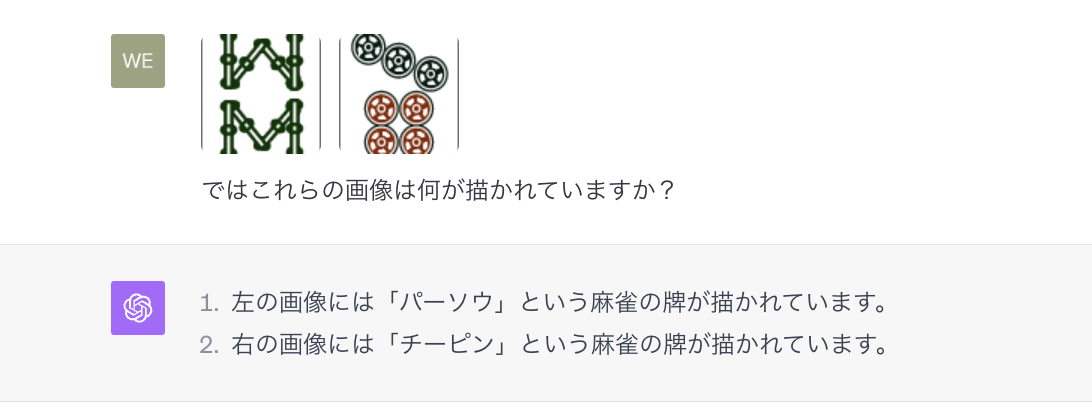
ではこれらの画像は何が描かれていますか?
ChatGPT
左の画像には「パーソウ」という麻雀の牌が描かれています。
右の画像には「チーピン」という麻雀の牌が描かれています。
お見事です。
教えたことは理解できているようです。
ここら辺までは、プロンプトチューニング、few shotなど、いろんな呼び名がありますが、まあそんな感じの攻め方ですね。
これらをファインチューニングのように記憶できればいいのですが、今のところGPT-4のファインチューニングはできない上、できても簡単な質問応答タスクのみなので、画像認識云々ができないですね。
なので、このプロンプトを記憶している間は、認識できます。
ここらあたりはGPT-4の今後の改善点かもですね。
ユーザー側で詳細の情報を入れられるようにできればいいのですが、言い換えれば、嘘の情報も入れられるとGPT側はまずいでしょうから難しいのかも。
とりあえず今回はここまで。
プロンプトで教えると、なんとか理解できるってことはわかりました。
この後もいろいろテストしてみたのですが、長くて。
正直言うと、麻雀牌の画像認識の精度は、そうですねえ、おおむね60〜80パーセントくらいの出来でしょうか。
やはり漢字は苦手ですかね。また白 ハツ 中あたりをたまに間違えますね。
その辺のところは、今後少しづつ書いていきまーす。
(その根気が続くのだろうか 笑)

Follow me!