
X 旧Twitterはこちら。
https://twitter.com/ison1232
***********
大規模言語モデルのFalconを実装していく
Falconとか言う大規模言語モデル LLMがオープンソースで公開されたようなので、早速google colabで動かしてみました。
Hugging Faceのオープンソース大規模言語モデル同士でスコアを競う「Open LLM Leaderboard」というランキングで
「Falcon-40B」モデルが1位を獲得したとか。
Falcon公式サイト
https://falconllm.tii.ae/
各社が独自の大規模言語モデルのLLMを作り始めた
最近は大規模言語モデルが結構いろんな団体からリリースされてます。
OpenAIのChatGPTクラスの超パラメータのLLMとかだと、事前学習するだけでも結構なコストがかかるようです。
なので、資金力があるところしかLLMを開発できなそうですが、実は、学習に使うデータセットの質を上げれば、パラメータ数が小さくても、それなりのAIは開発できるようです。
ただ、どうなんですかね。
Scaling Laws理論によればパラメータを増やすほど、AIの能力が上がっていくって説があります。
要はAGI(汎用人工知能)のすごいやつ、超絶AIっていうのでしょうか、人間の人智の遥か上をいくスーパーAIを作るとなると、やはり数兆単位のパラメータは要るかもしれないですね。
しかし、日常で使う会話程度の生成AIであれば、数十億パラメータでも、学習次第で十分な結果が出ると。
そんなところでしょうか。
この超絶AIはいつか必ずどこかが作るでしょうね。
それによって、人類が解決できなかった、いろんな事(核、医療、創薬、難問など)が解ける時代が来るのでしょう。
そのためにも、超絶AIは必要でしょう。
しかし、どこかでブレーキをかける術も作っておかないと、AIの暴走なんかも起こらないとも言えない。
電源を止めれば大丈夫ってな意見もありますが、超絶AIは電源を止められない何かを作りだすかも知れません。
人類の数千倍とかの知能を持ったとしたら、我々の考えつかない何かを作り出す可能性はあります。
OpenAIのCEOサム・アルトマンが、AI開発には原子力のような規制機関が必要との見解を出しましたが、
最先端の技術者ほど、AIの真の力がわかっているのではないでしょうか。

google colabでFalconを実装していく
さて、日常の会話程度をうまくこなす生成AIでしたら、今回のFalconの小さい方のモデルで十分です。
早速、google colabで実装してみましょう。
ちなみに、ランタイムでGPU、タイプT4、ハイメモリで実行しています。
!pip install transformers accelerate einops
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = “tiiuae/falcon-7b-instruct”
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
“text-generation”,
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map=”auto”,
)
prompt = “What will the future of generative AI look like?”
sequences = pipeline(
prompt,
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f”Result: {seq[‘generated_text’]}”)
実装後の推論部分を見てみましょう。
英語でのやり取りですけど、結構ちゃんと答えてくれます。
問い:
What will the future of generative AI look like?
生成AIの未来はどうなるでしょうか?
結果:
The future of generative AI looks very bright, indeed. With the advent of more powerful hardware and algorithms, AI has become more intelligent and efficient than ever before.続く…。
ジェネレイティブAIの未来は、実に明るいものになりそうです。より強力なハードウェアとアルゴリズムの登場により、AIはかつてないほどインテリジェントで効率的になりました。アプリケーションの面でも、その可能性は無限に広がっています。私たちが想像する最もエキサイティングな開発には、次のようなものがあります。続く…。
*******
改変する場合は、prompt = “○○○○” の部分を変えればいろんな質問が試せます。
また、max_length=200の数値を大きくすれば、さらにたくさんの言葉が返ってきます。
いろいろ改変してみてください。
一度上記のコードが動けば、あとはプロンプトを変えて下記だけ実行した方が処理は早いです。
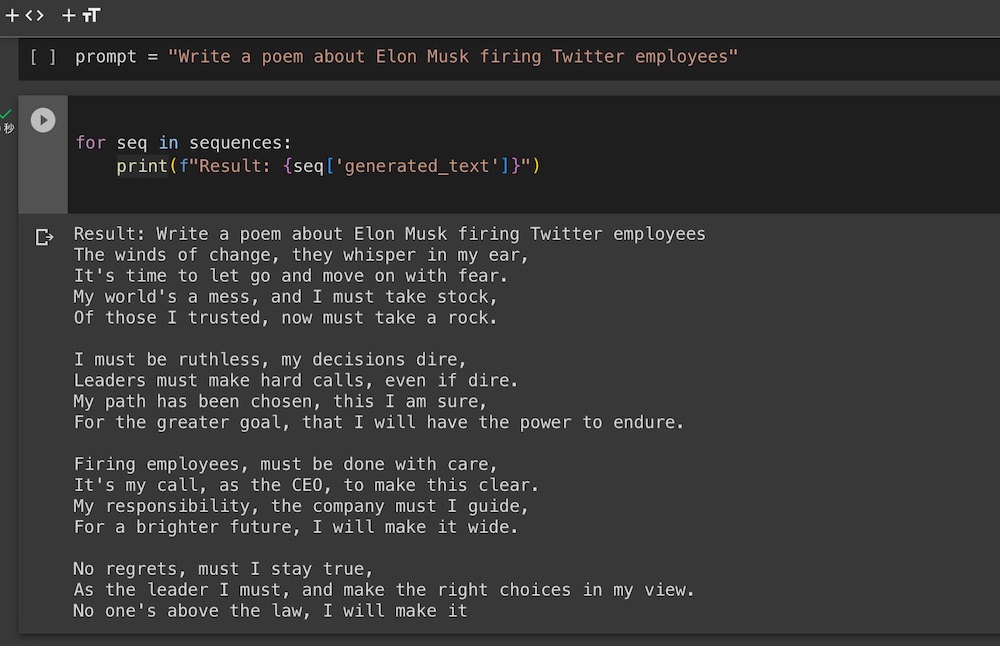
prompt = “Write a poem about generative AI”
sequences = pipeline(
prompt,
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f”Result: {seq[‘generated_text’]}”)
●実装が面倒な方は、公式Falconでチャットボットが用意してあります。
下記からお試しください。
https://huggingface.co/spaces/HuggingFaceH4/falcon-chat
●有志の方が、下記のリンクからパラメータが小さい方の「Falcon-7B-Instruct」をgoogle colabでの実装公開しています。
興味のある方はぜひ。
各社の大規模言語モデルをいじってみての感想
大規模言語モデルの新しいのが出ると、つい試したくなりますね。
英語での学習モデルが多いのですが、日本語で学習したサイバーエージェントのモデルとかrinna社のモデルとかも出ているので、興味のある方は試してください。
パラメータが大きいに越したことはないですが、あまりに大きいと通常のPCとかでは動かせないですよね。
なので適度な大きさのモデルで実装できるのが楽しいですね。
まあ自分のPCで動かさなくても、ChatGPTのようにブラウザやアプリからアクセスして使うのも全然ありなんですが、開発者としてはコードを見ながら、一行づつ実行している様を見るのも楽しいんですよね。
「開発者あるある」なんではないでしょうか。
ぜひみなさんもお試しください。