********
※LINE対応チャットボット版の
「LINEチャットボット屋」
いろんなチャットボットがあります。
ぜひ、ご覧ください!
***************

***************
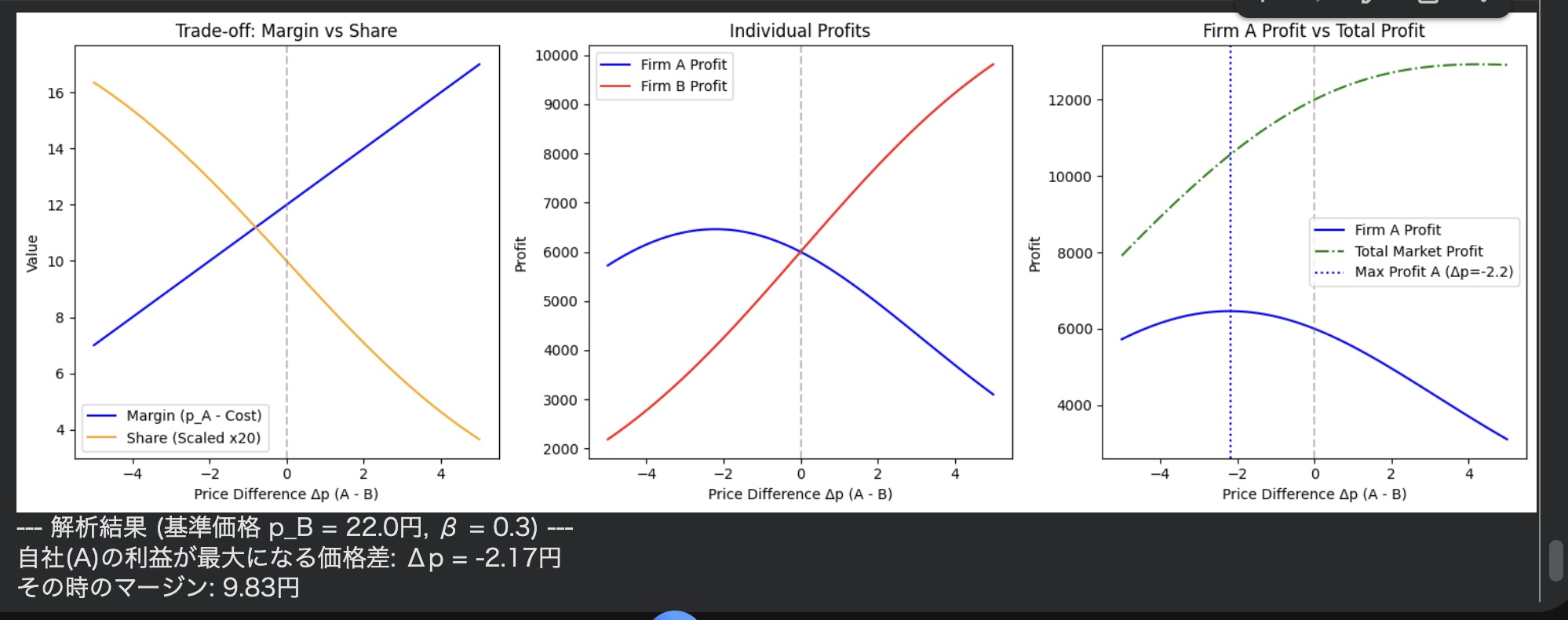
小型モデルを回答&分析に使うメリット
小型の生成AIモデルで、どこまで実用的なことができるのかを試します。
そこで今回は、GoogleのGemma-2Bを使って、RAGの簡単なテストをしてみました。
小型モデルを使う利点は、大型モデルと違って、社内にシステムを置けるので、情報漏洩がしづらいと言うところです
chataGPTなどの大型モデルを使うと、社内の資料をアップロードしないといけないので、情報が外に漏れてしまいます。
こういったことを気にしないで活用できるのが、小型モデルの良いところでしょう。
さて、RAGは外部の資料を検索して、その内容をもとに回答&分析を作る仕組みです。
モデルが元から知っている知識だけで答えるのではなく、自分で資料を参照しながら返答するので、うまく作れれば特定の文書に強いAIを作ることができます。
有名なシステムでわかりやすいのはGoogleの出しているnotebook LMです。
ただしあちらはサーバ上で動いているので、やはり社内などの文章をアップロードすると、情報が漏れるって言う、いいんだか悪いんだかが起きますね。
そこで今回は、大がかりな本番システムを作らず、まずはGoogle Colab上で動くシンプルな構成で、Gemma-2Bのような比較的小さなモデルでもRAGらしい動きができるのかを確かめてみました。

そもそもRAGとは何か
RAGは、日本語では「検索拡張生成」などと呼ばれます。
ざっくり言えば、まず質問に関連する文章を資料の中から探し、その検索結果を生成AIに渡して回答や分析をさせる仕組みです。
普通のチャットAIは、学習済みの知識をもとに答えます。
しかしRAGを使うと、手元のテキストファイルや社内文書、マニュアル、議事録、取引先データなどを参照しながら答えさせることができます。
つまり、モデル自体を追加学習しなくても、ある程度その場で知識を補えるわけです。
この仕組みの面白いところは、モデルのサイズがそれほど大きくなくても、参照資料がしっかりしていれば役立つ回答&分析ができることです。
逆に言えば、モデルそのものの性能だけでなく、資料の分け方や検索精度がかなり重要になります。
今回のテストでも、まさにそこがポイントになりました。
今回の環境と使用した諸々
今回の実験環境はGoogle Colabです。
ローカル環境を整えなくても始めやすく、ちょっとしたRAGの試作にはかなり便利です。
役割としては、Gemma-2Bが回答生成を担当し、SentenceTransformerがテキストの埋め込みを作り、FAISSがベクトル検索を担当します。
Gradioは簡単な操作画面を作るために使いました。
これにより、Hugging Faceのトークンを入力してモデルを初期化し、テキストファイルをアップロードし、質問を入力して回答を得る、という一連の流れをブラウザ上で試せるようにしました。
最初はとにかく最小構成で動かすことを優先し、1セルで完結するコードにしていました。
こういう形は試行錯誤しやすい反面、後から見ると雑な実装になりやすく、精度面でも改善の余地が多いですね。

実装してみてつまずいたポイント
実際に組んでみると、最初から順調に進んだわけではありません。まず単純な構文ミスがありました。
関数定義の引数のところに余計な文字が混ざっていて、それだけでエラーになります。
こういうミスは地味ですが、Colabで一気に書いていると意外と起きやすいです。
ファイル読み込みや空入力に対する例外処理も必要でした。
こうした部分をちゃんと整えるだけでも、実験コードとしてかなり扱いやすくなります。
RAGは検索や生成の精度に目が行きがちですが、その前にまずシステムが落ちずに動かすことだと、あらためて感じました。
なぜ最初は精度があまり出なかったのか
動くようになってから試してみると、精度はあまり高くありませんでした。
質問に対して少しずれた回答をしたり、資料に書かれていないことをうまく拾えなかったりします。
最初はGemma-2Bという小型モデルの限界かなと思ったのですが、見直してみると、原因はモデルだけではありませんでした。
一番大きかったのは、テキストの分割方法です。
最初は単純に文字数で区切っていたので、文の途中で分かれたり、見出しと本文が離れたりして、検索しにくい断片が大量にできていました。
これでは、検索で拾う文章の質が下がってしまいます。
もう一つは埋め込みモデルです。最初は英語寄りの埋め込みモデルを使っていたため、日本語のテキストを扱うには相性がいまひとつでした。
さらに、検索時に取る件数が少なすぎると、たまたま外したときにそのまま精度低下につながります。
つまり、生成モデルの前段階である検索部分に改善余地がかなりあったわけです。
チャンク分割や検索方法を見直してみた
そこで、精度改善版ではまずチャンク分割を見直しました。
文字数で機械的に切るのではなく、段落ベースでまとめ、長すぎる段落だけ追加で分割するようにします。
これだけでも、意味のまとまりが保たれやすくなり、検索の質が上がります。
さらに overlap を入れて、前後の文脈が多少つながるようにしました。
埋め込みモデルも、多言語対応の intfloat/multilingual-e5-base に変更。
日本語の資料を扱うなら、こうした多言語系のモデルのほうが安定感があります。
加えて、E5系の推奨に合わせて、文書側には passage:、質問側には query: という接頭辞を付けて埋め込みを作るようにしました。
検索部分では、FAISSのIndexFlatL2からIndexFlatIPに変更。
埋め込みを正規化して使うなら、内積ベースのほうが相性が良いケースがあります。
また、検索件数も top_k=3 から top_k=5 に増やしました。これにより、関連文脈を取りこぼしにくくなりました。
さらに、デバッグのために「実際に検索で拾った文脈をそのまま表示する機能」も付けました。これがかなり便利で、精度が悪い原因が検索側なのか、生成側なのかを切り分けやすくなりました。

小型モデルでRAGを試す面白さ
今回試してみて感じたのは、Gemma-2Bのような小型モデルでも、RAGの基本構成を理解したり、簡単な実験をしたりするには十分面白いということです。
もちろん、大型モデルに比べると読解力や回答の安定性には差がありますし、複雑な質問では限界も見えます。
ただし、RAGではモデル本体だけでなく、資料の整え方、チャンク分割、埋め込みモデル、検索方法などが全体の精度に大きく効きます。
つまり、小型モデルだから駄目と決めつけるのではなく、周辺設計を丁寧に詰めることでかなり改善できる余地があります。
今回のテストは、まさにそのことを実感する機会になりました。
最初は「何となく動いた」段階でしたが、検索部分をきちんと見直すことで、回答の納得感がかなり変わってきます。
RAGは単なる生成AIの応用ではなく、検索設計まで含めた総合戦だとよく分かります。
もしこれから試すなら、まずは小さく作って動かし、検索結果の確認機能を入れながら、少しずつ精度を詰めていくのがおすすめです。
Gemma-2Bを使った今回の実験は、その第一歩としてかなり面白い実験でした。
必要以上に大きな構成にせず、まずは手軽に試してみる。それだけでも、RAGの勘所はかなりつかめると思います。
今回使用したコード
*表示のバグでインデントが崩れています。
コピーしてお気に入りのAIに直してもらってください。
# -*- coding: utf-8 -*-
"""
Gemma-2B RAG System (All-in-One Cell) - Accuracy Improved Version
Google Colab 用
"""
# ==========================================
# 1. ライブラリのインストール
# ==========================================
!pip install -q transformers sentence-transformers faiss-cpu gradio accelerate
# ==========================================
# 2. インポート
# ==========================================
import os
import re
import faiss
import gradio as gr
import numpy as np
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from sentence_transformers import SentenceTransformer
# ==========================================
# 3. グローバル変数
# ==========================================
model = None
tokenizer = None
embedder = None
index = None
chunked_texts = []
# ==========================================
# 4. ユーティリティ
# ==========================================
def get_torch_dtype():
if torch.cuda.is_available():
return torch.float16
return torch.float32
def get_model_input_device():
try:
return next(model.parameters()).device
except Exception:
return torch.device("cuda" if torch.cuda.is_available() else "cpu")
def clean_text(text):
if not text:
return ""
text = text.replace("\r\n", "\n").replace("\r", "\n")
text = re.sub(r"\n{3,}", "\n\n", text)
text = re.sub(r"[ \t]+", " ", text)
return text.strip()
# ==========================================
# 5. システム初期化・リセット
# ==========================================
def initialize_system(hf_token):
global model, tokenizer, embedder, index, chunked_texts
index = None
chunked_texts = []
try:
model_id = "google/gemma-2b-it"
if tokenizer is None:
tokenizer = AutoTokenizer.from_pretrained(
model_id,
token=hf_token if hf_token else None
)
if model is None:
dtype = get_torch_dtype()
model = AutoModelForCausalLM.from_pretrained(
model_id,
token=hf_token if hf_token else None,
device_map="auto",
torch_dtype=dtype
)
model.eval()
# 精度重視で small → base に変更
if embedder is None:
embedder = SentenceTransformer("intfloat/multilingual-e5-base")
dimension = embedder.get_sentence_embedding_dimension()
# normalize_embeddings=True と相性のよい Inner Product 検索
index = faiss.IndexFlatIP(dimension)
return "システム初期化完了(データはリセットされました。新しいファイルをアップロードしてください)"
except Exception as e:
return f"初期化エラー: {str(e)}"
# ==========================================
# 6. 精度改善版テキスト分割
# - 段落ベース
# - 長すぎる段落のみ追加分割
# ==========================================
def split_text(text, chunk_size=500, overlap=100):
text = clean_text(text)
if not text:
return []
paragraphs = [p.strip() for p in text.split("\n\n") if p.strip()]
chunks = []
current = ""
for para in paragraphs:
# 今の current に追加できるなら追加
if len(current) + len(para) + 2 <= chunk_size: current += ("\n\n" + para) if current else para else: if current: chunks.append(current) # 段落自体が長すぎるならスライド分割 if len(para) > chunk_size:
start = 0
while start < len(para): end = min(start + chunk_size, len(para)) chunk = para[start:end].strip() if chunk: chunks.append(chunk) if end >= len(para):
break
start += chunk_size - overlap
current = ""
else:
current = para
if current:
chunks.append(current)
# 空要素除去
chunks = [c.strip() for c in chunks if c and c.strip()]
return chunks
# ==========================================
# 7. ファイル読み込み・保存
# ==========================================
def process_and_store_file(file_obj):
global index, chunked_texts, embedder
if index is None:
return "先に [Initialize / Reset System] ボタンを押してください。"
if file_obj is None:
return "ファイルが選択されていません。"
try:
file_path = getattr(file_obj, "name", None)
if file_path is None:
file_path = file_obj
with open(file_path, "r", encoding="utf-8") as f:
text = f.read()
except UnicodeDecodeError:
return "エラー: ファイルの文字コードがUTF-8ではありません。"
except Exception as e:
return f"ファイル読み込みエラー: {str(e)}"
text = clean_text(text)
if not text:
return "エラー: ファイルの中身が空です。"
chunks = split_text(text, chunk_size=500, overlap=100)
if not chunks:
return "テキストを分割できませんでした。ファイル内容を確認してください。"
try:
passages = [f"passage: {c}" for c in chunks]
embeddings = embedder.encode(
passages,
convert_to_numpy=True,
normalize_embeddings=True,
show_progress_bar=False
).astype("float32")
index.add(embeddings)
chunked_texts.extend(chunks)
except Exception as e:
return f"埋め込み保存エラー: {str(e)}"
return (
f"完了: {os.path.basename(file_path)} から "
f"{len(chunks)} チャンクの情報を記憶しました。"
)
# ==========================================
# 8. 検索
# - top_k を 5 に増量
# - デバッグ用にスコア付き検索も返せるように
# ==========================================
def retrieve_context(query, top_k=5, return_debug=False):
global index, chunked_texts, embedder
if index is None or index.ntotal == 0:
return "" if not return_debug else []
if not query or not query.strip():
return "" if not return_debug else []
try:
query_embedding = embedder.encode(
[f"query: 次の質問に関連する箇所を資料から探してください。質問: {query}"],
convert_to_numpy=True,
normalize_embeddings=True,
show_progress_bar=False
).astype("float32")
k = min(top_k, index.ntotal)
scores, indices = index.search(query_embedding, k)
results = []
for score, idx in zip(scores[0], indices[0]):
if idx != -1 and 0 <= idx < len(chunked_texts):
results.append({
"score": float(score),
"text": chunked_texts[idx]
})
if return_debug:
return results
return "\n---\n".join([r["text"] for r in results])
except Exception:
return "" if not return_debug else []
# ==========================================
# 9. 検索結果確認用
# ==========================================
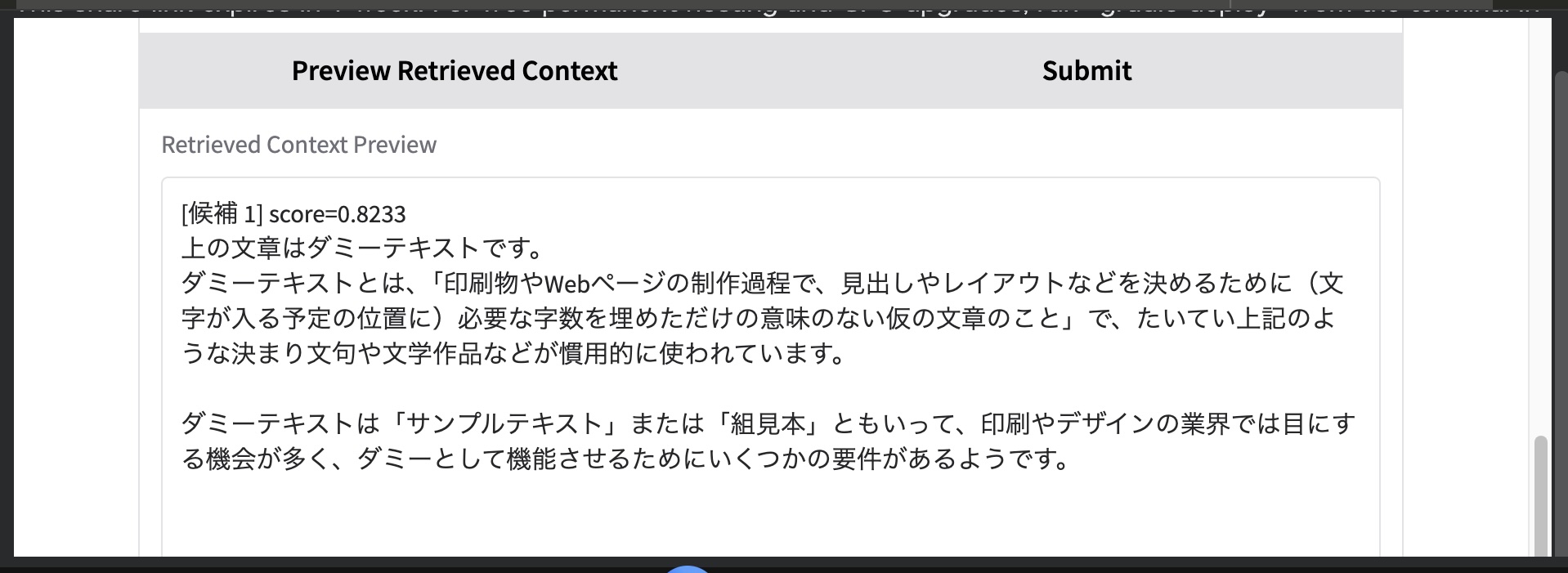
def preview_retrieved_context(query):
if model is None or tokenizer is None:
return "エラー: システムが初期化されていません。"
if not query or not query.strip():
return "質問を入力してください。"
results = retrieve_context(query, top_k=5, return_debug=True)
if not results:
return "関連する情報が見つかりませんでした。"
lines = []
for i, item in enumerate(results, start=1):
lines.append(f"[候補 {i}] score={item['score']:.4f}\n{item['text']}")
return "\n\n==============================\n\n".join(lines)
# ==========================================
# 10. 回答生成
# ==========================================
def generate_answer(query):
global model, tokenizer
if model is None or tokenizer is None:
return "エラー: システムが初期化されていません。"
if not query or not query.strip():
return "質問を入力してください。"
context = retrieve_context(query, top_k=5)
if not context:
return "アップロードされた資料の中に、関連する情報が見つかりませんでした。"
prompt = f"""あなたは資料の内容に忠実なアシスタントです。
以下の[参照資料]だけを根拠に回答してください。
資料にないことは「資料には書かれていません」と答えてください。
推測や想像で補完してはいけません。
回答は簡潔かつ具体的に述べ、必要なら箇条書きで示してください。
[参照資料]
{context}
[質問]
{query}
[回答]
"""
try:
input_device = get_model_input_device()
inputs = tokenizer(
prompt,
return_tensors="pt",
truncation=True,
max_length=2048
)
inputs = {k: v.to(input_device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=256,
do_sample=False
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
answer = generated_text[len(prompt):].strip()
if not answer:
return "回答を生成できませんでした。"
return answer
except Exception as e:
return f"回答生成エラー: {str(e)}"
# ==========================================
# 11. UI構築
# ==========================================
with gr.Blocks() as demo:
gr.Markdown("## Gemma-2B RAG System(精度改善版)")
with gr.Group():
gr.Markdown("### 1. 初期化(リセット)")
with gr.Row():
token_input = gr.Textbox(
label="Hugging Face Token",
type="password",
placeholder="hf_..."
)
init_btn = gr.Button("Initialize / Reset System")
init_status = gr.Textbox(label="Status", interactive=False)
init_btn.click(fn=initialize_system, inputs=token_input, outputs=init_status)
gr.Markdown("---")
with gr.Group():
gr.Markdown("### 2. テキストファイルをアップロード")
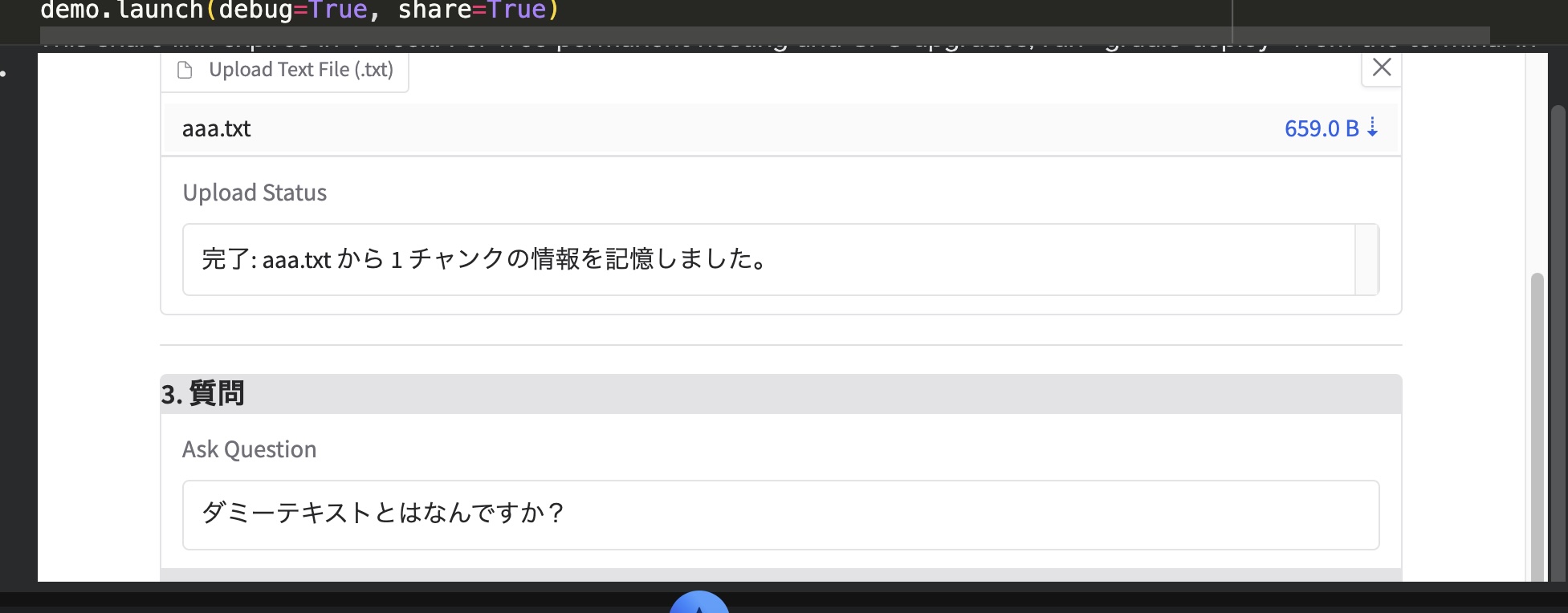
file_input = gr.File(label="Upload Text File (.txt)", file_types=[".txt"])
upload_status = gr.Textbox(label="Upload Status", interactive=False)
file_input.upload(fn=process_and_store_file, inputs=file_input, outputs=upload_status)
gr.Markdown("---")
with gr.Group():
gr.Markdown("### 3. 質問")
query_input = gr.Textbox(
label="Ask Question",
placeholder="例: この資料の要点は?"
)
with gr.Row():
preview_btn = gr.Button("Preview Retrieved Context")
submit_btn = gr.Button("Submit")
preview_output = gr.Textbox(label="Retrieved Context Preview", lines=14)
answer_output = gr.Textbox(label="Answer", lines=10)
preview_btn.click(fn=preview_retrieved_context, inputs=query_input, outputs=preview_output)
submit_btn.click(fn=generate_answer, inputs=query_input, outputs=answer_output)
demo.launch(debug=True, share=True)
****************
最近のデジタルアート作品を掲載!
X 旧ツイッターもやってます。
https://x.com/ison1232
インスタグラムはこちら
https://www.instagram.com/nanahati555/
**************